12 MIN READ
FIELD NOTE
OTTO · OWNING AI QUALITY
APPLIED ACROSS ORGS
2026
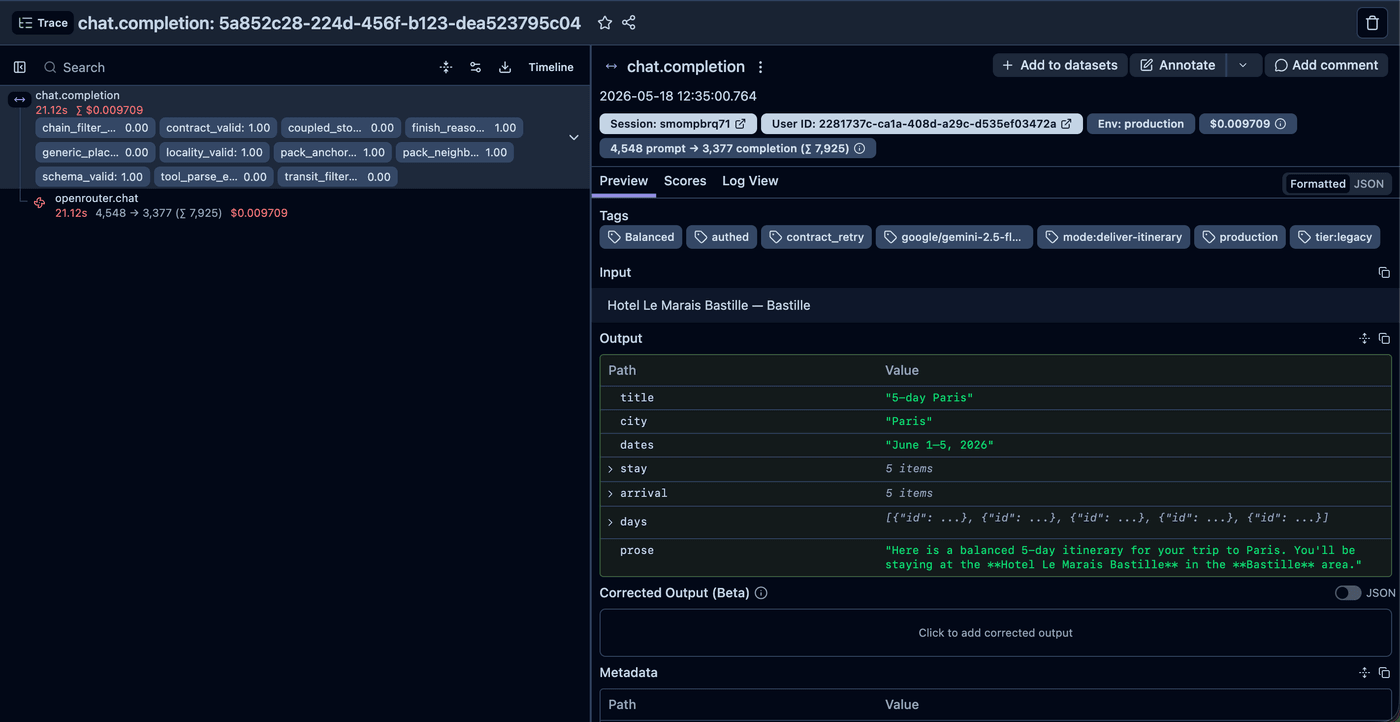

Otto is a concept I built and ran end-to-end. It’s a chat-first travel planner, and I used it to work out one claim I keep hitting at work: AI quality is a product you own. No model vendor decides what “wrong” means for your product. I’ve owned this same problem with teams across organisations, on critical AI where the data is live and the rules keep moving. Quality isn’t a QA step at the end. It’s typed contracts, guardrails, evals, traces, and a gate that won’t ship bad output. Below is what I built, and the 392 km bug that shaped it.
I’ve spent eleven years in product, six of them as a product manager - marketplaces, dashboards, platform tooling. I kept watching teams ship AI features the way they’d ship anything else: write the prompt, wire up the API, call it done. That breaks the moment the thing underneath is non-deterministic. The same prompt returns a different answer tomorrow, and when it’s wrong, the answer still comes out fluent, well-formed, confident, and false.
The question it poses is one I keep meeting for real: when a model writes the output, who owns whether it’s right? On a concept I built alone, the answer was me. Inside an organisation it’s the same answer, split up. The PM owns the definition of quality and the bar, and drives the build with the team. No model vendor decides what “wrong” means for your product. So I treat AI quality as a product surface I own, and Otto is where I worked out what that takes.
I picked travel on purpose, because the failure modes are easy to measure. A wrong restaurant is a five-minute walk. A wrong city is a same-day flight you can’t undo.
The model put a real Osaka hotel inside a Tokyo itinerary. A confident, well-formed lie no schema check would catch.
Early on I asked Otto for five days in Tokyo. The plan came back typed, valid, and well written. Day 2 anchored to a real, well-reviewed, correctly-priced hotel: the Hyatt Regency Osaka. That hotel is 392 kilometres from Tokyo, in a different city. Every structural test passed. The data was valid and the output was wrong.
That one bug is why this guardrail exists. I couldn’t fix it with a better prompt, and validation couldn’t catch it, because there was no defect to catch. The data was correct. The only thing that catches it is a guardrail that knows the destination and rejects anything outside a set radius. I had to pick that radius, so I did: 100 km, hard fail.
On Otto I wore every hat because it was mine to build. On a team the work is the same, just shared. You write down exactly what “wrong” looks like: wrong place, wrong city, wrong price tier, brochure voice. You build the machinery that refuses to ship it, with the people who can build it. Then you hold the gate. That’s five surfaces, and each one is a decision the PM owns and the team enforces. None of it is exotic engineering. It’s product judgement, written down.
Quality used to be the last thing I checked. On Otto I designed it first - the layer between the model and the user. What changed for me
Each layer settles one question I had to answer myself, from what the model may say to what’s allowed to ship.
I split the model’s two jobs. Typed function calls route every question. Strict templates carry every piece of content. I decide what it can say and in what shape. A production bug taught me why that split matters.
Three checks I wrote and own: is the place within range of the destination, does the price tier hold together, is the voice free of “hidden gem” filler. They run after the output is already structurally valid, because that’s when the wrong answers slip through.
I pin the model so the same input gives the same output, then replay 16 saved conversations on every change. Five of them are deliberately broken, so the system has to catch them. It catches all five or the change doesn’t ship.
Every model call and every guardrail verdict is logged. When something’s wrong, I read the trace and see exactly where it went wrong. I don’t reproduce it from scratch.
The evals run automatically before anything ships. Red means it doesn’t go out. No override, no “we’ll fix it next sprint.” I set the bar, and I defend it when the pressure says lower it.
Of the five, the evals are the part I’m proudest of. They’re where “I own quality” stops being a claim and turns into a number. Each eval is my definition of wrong, written down so a machine can check it. Stack up enough of them and my judgement is a test suite the product has to pass on every change.
I learned this the slow way. Early on I lost two weeks unable to tell signal from noise, because I had no way to replay anything. Every “improvement” was a gut feeling, and I damaged my own intuition chasing results I couldn’t prove. So I built eval mode: fixed settings, saved conversations, planted failures that have to be caught. After that a green run meant something.
Here’s the machinery itself: the eval-mode pin and the locality threshold, in my own code.
// Eval mode pins determinism so two runs of the // same conversation can’t differ on sampling noise. export const EVAL_TEMPERATURE = 0; export const EVAL_TOP_P = 0.1; export const EVAL_SEED = 42; export function pinForEval(body) { if (body.temperature == null) body.temperature = EVAL_TEMPERATURE; if (body.top_p == null) body.top_p = EVAL_TOP_P; if (body.seed == null) body.seed = EVAL_SEED; return body; }
// Are the model’s map items within a sensible radius // of the destination? Catches the bug class where a // “Day 2” item lands in the wrong city - valid // coords, semantically wrong. Default 100 km. export function isWithinDestination(items, center, radiusKm = 100) { for (const item of items) { const dist = haversineKm(item, center); if (dist > radiusKm) outside.push({ name: item.name, distanceKm: dist }); } return { valid: outside.length === 0, outside }; }
The AI-era PM job is owning the seam between a model that can be wrong and a user who trusts it. Writing prompts is the small part of it. I learned to write my definition of wrong where a machine can enforce it, to instrument before I optimise (two weeks taught me that the hard way), and to keep a gate I’d actually stand behind.
The contracts, guardrails, evals, traces, and gate outlast every model swap. Change the model and they all still hold. The demo gets the attention. This is the part I want to keep doing.